
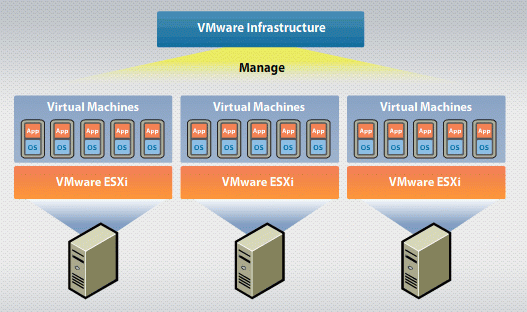
VMware HA and DRS Explained
Virtualizing an infrastructure and running virtual resources to serve out business-critical workloads having many great advantages. As we can say VMware vSphere, it provides many notable features and capabilities that deliver high-availability in the environment as well as automated workload scheduling to ensure the most efficient use of hardware and resources in a vSphere environment.
Here we will talk about two core cluster-level features of vSphere in the enterprise – vSphere HA and DRS. You have seen both of these referenced along with running vSphere in the enterprise.
There are many questions in peoples mind like, what is vSphere HA and DRS? What do they do? How do you benefit by running both in your vSphere environment?
Let’s take a look at a basic introduction to HA and DRS in VMware vSphere and see how they compare and the benefits of using them.
VMware vSphere Clusters
One of the advantages & best practices when utilizing VMware vSphere to run business-critical workloads is to run a vSphere Cluster.
What is a vSphere Cluster?
In a simple words a vSphere cluster is a configuration of more than one VMware ESXi server aggregated together as a pool of resources contributed to the vSphere cluster. We can say Resources such as CPU compute, memory, & in the case of software defined storage such as vSAN, storage, are contributed by each ESXi host.
Why is running your business-critical workloads on top of a vSphere Cluster important?
- The advantages provided by running a hypervisor is it allows more than one server to run on top of a single set of physical hardware. By Virtualizing workload provides many efficiency benefits in orders of magnitude when compared to running a single server on a single set of physical hardware.
- Although, this can also become the Achilles heel of a virtualized solution, since the impact of a hardware failure can affect many business-critical services & applications. Let’s say if you only have a single VMware ESXi host running many VMs, the impact of losing that single ESXi host would be immense.
- Here we will learn many things like, how does simply running multiple hosts in a cluster enhance your high-availability? How does a host in the vSphere Cluster “know” if another host has failed? Is there a special mechanism that is used to take care of managing the high-availability of workloads running on a vSphere Cluster? Yes, there is. Let’s see.
What is HA in VMware?
VMware found the need to have a mechanism to be able to deliver protection against a failed ESXi host in the vSphere Cluster. Therefore, VMware High-Availability (HA) was born.
VMware vSphere HA has the following benefits:
- It is cost-effective. It allows automated restarts of VMs and vSphere hosts when there is a server outage or an OS failure detected in the vSphere environment.
- It Monitors all VMware vSphere hosts & VMs in the vSphere Cluster. VMware vSphere delivers high-availability to most applications running in virtual machines regardless of the operating system and applications.
- The good thing of VMware’s vSphere HA solution is that it implemented via the VMware Cluster is the simplicity & for which it can be configured. Having just few clicks through a wizard-driven interface, high-availability can be configured. How does this compare with traditional “clustering” technologies?
Windows Server Failover Clustering Comparison
- Windows Server Failover Clustering (WSFC) is become the clustering technology that most of us think it is. There is a one problem seen with WSFC is that it needs a lot of specialized expertise to run WSFC services correctly. Especially when it comes to upgrades, patching, and general operational tasks.
- If we Contrast vSphere HA with WSFC, the operational overhead is minimal by comparison with WSFC. We found a small chance that HA can be configured incorrectly as it is either enabled on a cluster or not. There are many considerations that need to be made when configuring WSFC to avoid both configuration and implementation mistakes. You will need to just think about the following:
- Failover clustering requires applications that support clustering (SQL, etc)
- Failover clustering requires quorum is configured correctly
- Not supported by many legacy operating systems and applications
- Requires complexity of cluster network names, resources, and networking
- To provide near zero-downtime at the application level, Windows Server Failover Clustering is advertised. When you add in the expertise required for a properly functioning HA solution, with the proper implementation of WSFC, the risks can begin to outweigh the benefits of using WSFC for high-availability of applications & services. This is especially true when for most businesses who may not truly need a “zero downtime” solution.
- However, vSphere HA does require a restart of the VMs on a healthy host when a failover occurs, it requires no installation of additional software inside the guest virtual machines. No complex configurations of additional clustering technologies, & applications or OS’s do not have to be designed to work with particular clustering technology.
- Legacy OS and applications generally have limited abilities when it comes to supported technologies to provide HA. Hence, there literally may be no native options to deliver failover functionality in the case of hardware failures.
- vSphere HA mechanism works & is simple to implement, configure, and manage. This is a technology that is well tested in thousands of VMware customer environments hence it has a stable and long history of successful deployments.
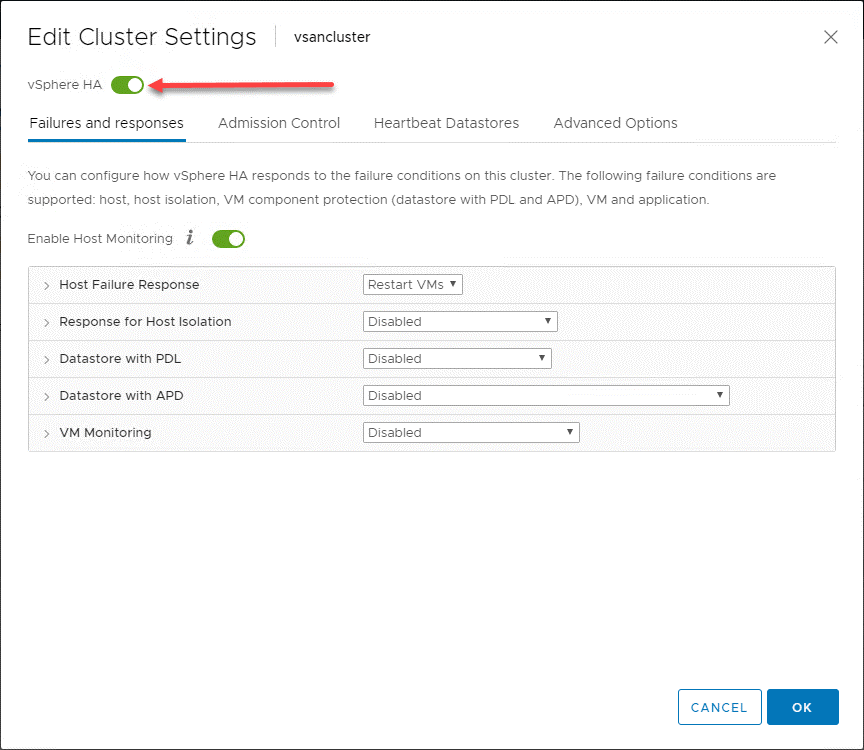
Image : VMware vSphere HA is a simple toggle button to turn the feature on at the vSphere Cluster level
General Overview of vSphere HA Behavior
The ESXi hosts in a vSphere Cluster provide the benefits, in its most basic form, & hence vSphere HA implements a monitoring mechanism between the hosts in the vSphere Cluster. The monitoring mechanism delivers a way to determine if any host in the vSphere Cluster has failed.
For Example: In the infographic given below, a two-node vSphere Cluster has experienced a failure of one of the ESXi hosts in the vSphere Cluster. The vSphere Cluster has vSphere HA enabled at the cluster level.
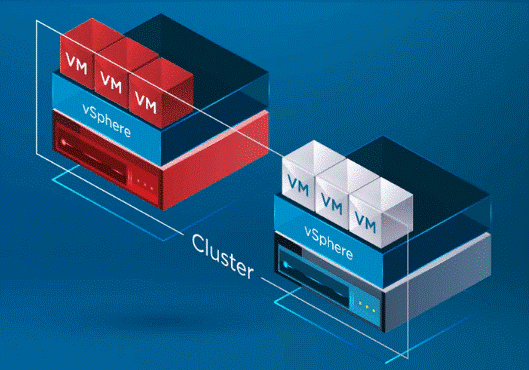
Image : Two ESXi hosts in a cluster with a failed
After recognition of vSphere HA, a host in the vSphere Cluster has failed, the HA process moves the registration of VMs from the failed host over towards the healthy host.
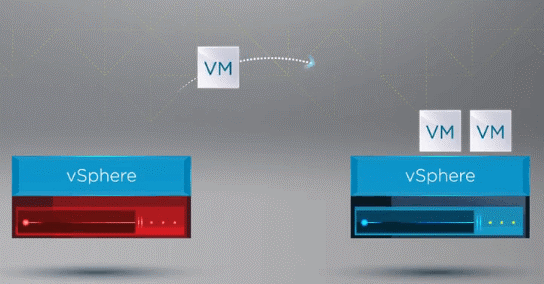
Image : Failed ESXi host VMs are moved to a healthy host in the vSphere cluster
After registering the VMs on a healthy host, vSphere HA restarts all the VMs of the failed host on a healthy ESXi host in the cluster, where the VMs were reregistered accordingly. The only downtime incurred is with the restart of the VMs on a healthy host in the vSphere Cluster.
VSphere HA Technical Overview
Prerequisites for vSphere HA
Here people may wonder what underlying prerequisites may be required in order for vSphere HA to work. To people simply need a VMware Cluster to enable HA? Unlike Windows Server Failover Clustering, there are only a few requirements that need to be in place for HA to work.
Requirements:
- At least two ESXi hosts
- At least 4 GB of memory configured on each host
- vCenter Server
- vSphere Standard License
- Shared storage for VMs
- Pingable gateway or another reliable network node
You can see there is no quorum component needed, no complex network naming added, and no other special cluster resources that need to be in place.
VMware vSphere HA Master vs Subordinate Hosts
After enabling vSphere HA on a cluster, a particular host in the vSphere Cluster is designated as the master of vSphere HA. The balance ESXi hosts in the vSphere Cluster are configured as subordinates in the vSphere HA configuration.
What role does the vSphere HA ESXi host that is designated as the master play? The vSphere HA master node:
- Monitors the state of the slave subordinate hosts – If your subordinate host fails the master host identifies which VMs need to be restarted.
- It Monitor the power state of all VMs that are protected. As If VM fails, then the master vSphere HA node ensures the VM is restarted.
- It keeps track of all the cluster hosts and VMs that are protected by vSphere HA.
- It is also renamed as the mediator between the vSphere Cluster & vCenter Server. The HA master reports the cluster health to vCenter and delivers the management interface to the cluster for vCenter Server.
- 0It Can run VMs themselves and monitor the status of VMs.
- It will also Stores protected VMs in cluster datastores.
vSphere HA Subordinate Hosts
- Run virtual machines locally
- Monitor the runtime states of the VMs in the vSphere Cluster
- Report state updates to the vSphere HA master
Master Host Election and Master Failure
How Can we Select the vSphere HA master host? When vSphere HA is enabled for a cluster, all active hosts participate in electing the master host. If the elected master host fails, then a new election takes place & where a new master HA host is elected to fulfill that role.
VMware vSphere HA Cluster Failure Types
Three types of failures that can happen to trigger a vSphere HA failover event in a vSphere HA enabled cluster. Those host failure types are:
- Failure – A failure is intuitively what you think. A host has stopped working in some form or fashion due to hardware or other issues.
- Isolation – The isolation of a host generally happens due to a network event that isolates a particular host from the other hosts in the vSphere HA cluster.
- Partition – A partition event is characterized by a subordinate host losing network connectivity to the master host of the vSphere HA cluster.
Heartbeating, Failure Detection, and Failure Actions
How does the master node determine if there is a failure of a particular host?
Following are several different mechanisms the master node uses to determine if a host has failed:
- The master node exchanges network heartbeats with the other hosts in the cluster every second.
- After the network heartbeat has failed, the master host checks for host liveness check.
- The host liveness check determines if the subordinate host is exchanging heartbeats with one of the datastores. Then it sends ICMP pings to its management IP addresses.
- If direct communication with the HA agent of a subordinate host from the master host is not possible and the ICMP pings to the management address fail, the host is viewed as failed and VMs are restarted on a different host.
- If it is found that the subordinate host is exchanging heartbeats with the datastore, the master host assumes the host is in a network partition or is network isolated. In this case, the master simply monitors the host and VMs
- Network isolation is the event where a subordinate host is running, but can no longer be seen from an HA management agent perspective on the management network. If a host stops seeing this traffic, it attempts to ping the cluster isolation addresses. If this ping fails the host declares it is isolated from the network
- In this case, the master node monitors the VMs that are running on the isolated host. If the VMs power off on the isolated host, the master node restarts the VMs on another host
Datastore Heartbeating
As mentioned above, one of the metrics used to determine failure detection is datastore heartbeating. What is this exactly? VMware vCenter selects a preferred set of datastores for heartbeating. Then, vSphere HA creates a directory at the root of each datastore that is used for both datastore heartbeating and for keeping up with the list of protected VMs. This directory is named .vSphere-HA.
There is an important note to remember regarding vSAN datastores. A vSAN datastore cannot be used for datastore heartbeating. If you only have a vSAN datastore available, there can be no heartbeat datastores used.
VM and Application Monitoring
Another extremely powerful feature of vSphere HA is the ability to monitor individual virtual machines via VMware Tools and restart any virtual machines that fail to respond to VMware Tools heartbeats. Application Monitoring can restart a VM if the heartbeats for an application that is running are not received.
- VM Monitoring – With VM Monitoring, the VM Monitoring service uses VMware Tools to determine if each VM is running by checking for both heartbeats and disk I/O generated by VMware Tools. In the event these checks fail, the VM Monitoring service determines most likely the guest operating system has failed and the VM is restarted. The additional disk I/O check helps to avoid any unnecessary VM resets if VMs or applications are still functioning properly.
- Application Monitoring – The application monitoring function is enabled by obtaining the appropriate SDK from a third-party software vendor that allows setting up customized heartbeats for the applications to be monitored by the vSphere HA process. Much like the VM Monitoring process, if application heartbeats stop being received, the VM is reset.
Both of these monitoring functions can be further configured with monitoring sensitivity and also maximum per-VM resets to help to avoid resetting VMs repeatedly for software or false positive errors.
VMware vSphere HA is a great way to ensure that your vSphere Cluster provides very resilient high-availability to protect against general host failures of ESXi hosts in your vSphere Cluster.
What about ensuring efficient use of resources in your vSphere Cluster? Let’s take a look at the next vSphere Cluster provision to help ensure efficient use of your vSphere Cluster resources and capacity.
What is DRS in VMware?
VMware Distributed Resource Scheduler (DRS) is a really powerful feature when running vSphere Clusters. It provides scheduling and load balancing across a vSphere Cluster. VMware DRS is the feature found in vSphere Clusters that ensures that virtual machines running inside your vSphere environment are provided with the resources they need to run effectively and efficiently.
VMs are generally subject to DRS early in life as from their first power on in a DRS-enabled cluster, DRS places the VMs on the best host configured to provide the required resources to the VM as soon as they are powered on. Additionally, DRS strives to keep vSphere clusters balanced from a resource usage perspective.
Even if a vSphere Cluster is balanced at a certain point in time, VMs may get moved around or change in such a way that an imbalance of cluster resources can creep back into the environment. When clusters become imbalanced, it can be detrimental to the overall performance of virtual machines running in a vSphere Cluster.
By default, DRS runs automatically on a vSphere cluster every five minutes to determine the balance of a vSphere Cluster and see if any changes need to be made to make more effective use of the resources.
VMware DRS Requirements
To take advantage of VMware DRS, there are several requirements that need to be met to ensure taking advantage of the Distributed Resource Scheduler functionality. These include:
- A cluster of ESXi hosts
- vCenter Server
- Enterprise Plus License
- vMotion is required for automatic load balancing
VMware DRS Actions
When VMware DRS runs on a vSphere Cluster every five minutes, it determines if there are any imbalances that exist in the cluster. If so, a vMotion will be performed to move designated VMs from one ESXi host to another.
How exactly does DRS determine if virtual machines are better suited on one ESXi host or another?
DRS runs a special algorithm to determine the right ESXi host that should house a particular VM. When a VM is powered on, this algorithm takes into consideration the resource distribution across the vSphere Cluster after it ensures there are no constraint violations if a particular VM is placed on a particular ESXi host.
Additionally, the demand of the VM itself is taken into consideration so the VM will hopefully never be starved for resources when it is powered on. What is included in VM demand? A VM’s demand includes the amount of resources needed to run.
- For CPU demand, this is calculated based on the amount of CPU the VM is currently consuming
- For memory, demand is calculated based on the formula: VM memory demand = Function(Active memory used, Swapped, Shared) + 25% (idle consumed memory). This shows the DRS memory balance is based mainly on a VM’s active memory usage while considering a small amount of its idle consumed memory as a cushion for any increase in workload.
DRS Automation Levels
One of t0he interesting features of DRS is the DRS automation levels. While DRS continues to scan the vSphere Cluster and provide recommendations every 5 minutes, you can determine whether or not DRS is able to enact its recommendations automatically or only suggest changes that should be made. DRS has three DRS automation levels. These include:
- Fully automated – In the fully automated approach, DRS applies both the initial placement and load balancing recommendations automatically
- Partially Automated – With partial automation, DRS applies recommendations only for initial placement of VMs
- Manual – In manual mode, you must apply the recommendations for both initial placement and load balancing recommendations
DRS Migration Thresholds
DRS includes very useful setting to control the amount of imbalance that will be tolerated before DRS recommendations will be made. There are five DRS migration thresholds that control the amount of imbalance tolerated.
The range is 1 (most conservative) to 5 (most aggressive).
With more aggressive settings, DRS tolerates less imbalance in a cluster. The more conservative, the more DRS tolerates imbalance.

Image: the VMware DRS Automation Level and Migration Threshold
VMware DRS VM/Host Rules
Here is an extremely useful feature that we found when using VMware DRS to control the placement of VMs in your vSphere DRS-enabled clusters. The VM/Host Rules allow to run specific VMs on specific ESXi host.
The VM/Host rules allow you to:
- Keep virtual machines together
- Separate virtual machines
- Tie Virtual Machines to specific hosts
- Tie Virtual Machines to virtual machines
Shown below is an example of creating a VM/Host rule for virtual machines and ESXi hosts.
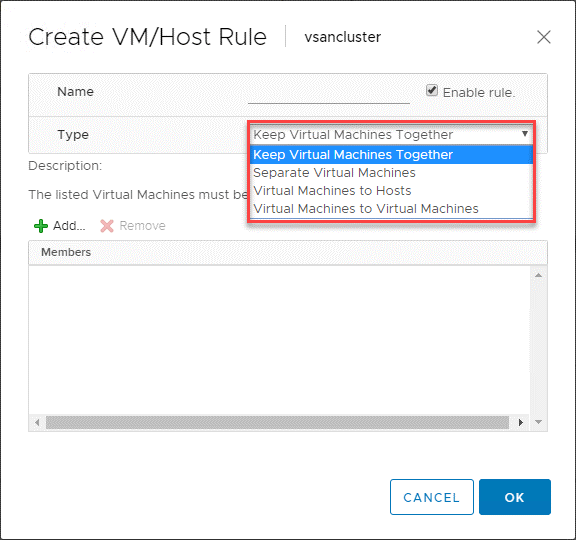
Image: VM/Host rules allow creating affinity between VMs and Hosts in a vSphere Cluster
Most of the classic use cases that exist is with domain controllers. While running all of your domain controllers in a virtualized environment like a vSphere Cluster, you want to make sure that you have your domain controller VMs separated from one another inside the cluster. In such way if you have an ESXi host go down along with one of your domain controllers, you still have a domain controller that is subject to a Separate Virtual Machines rule that is keeping it off the same host as another DC.
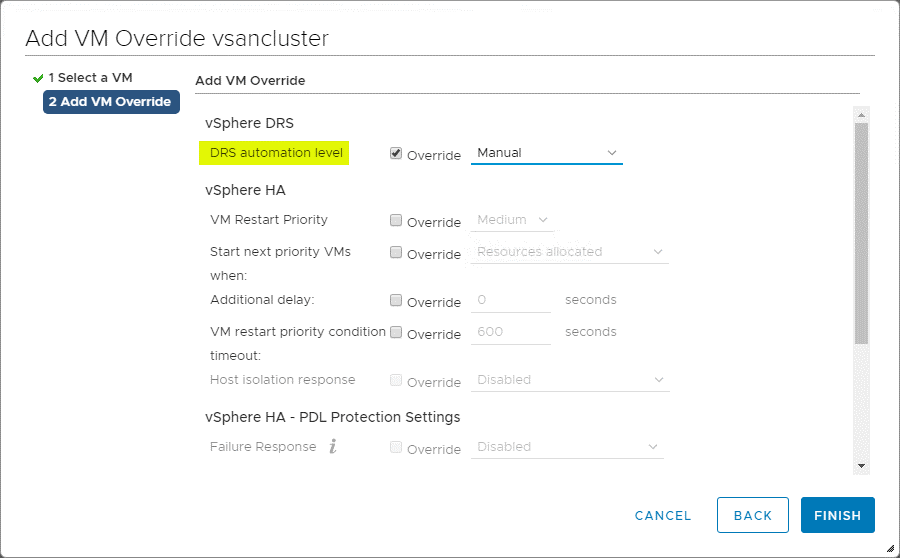
VM Overrides for DRS
The vSphere Cluster deliver great granularity for operations affecting individual VMs inside the vSphere Cluster. Here you can create VM Overrides to override global settings set at the cluster level for HA & DRS to define more specific settings for each VM.
CPU and Memory Utilization Summary
DRS provides a great high-level view of the CPU utilization summary of the CPU resources of ESXi hosts in the vSphere Cluster. Navigate to > Settings > Monitor > vSphere DRS > CPU Utilization.
Looking at CPU utilization summary using DRS in a vSphere Cluster
The same high-level overview can be viewed for memory consumption as well. Navigate to > Settings > Monitor > vSphere DRS > Memory Utilization
Is VMware vSphere HA and VMware DRS competing technologies?
No. It is highly recommended to use both vSphere HA and VMware DRS together to combine automatic failover with load balancing features and functionality.
After occurring failure of an ESXi host, vSphere HA will restart the VMs on the remaining healthy hosts in a vSphere Cluster. The first priority is the availability of virtual machine resources. VMware DRS will run and determine if any imbalance exists between the ESXi hosts running the workloads and will make recommendations to resolve any imbalances in the cluster based on the configured migration threshold. Based on the automation level, these recommendations will either be automatically actioned or only recommended if not fully automated.
Final Thoughts on VMware vSphere HA and DRS
In a production vSphere Cluster, running both VMware vSphere HA and DRS are highly recommended. These technologies help to make workloads highly-available & ensures they continuously have the resources needed based on the CPU demands of the VM.
By understanding working of both mechanisms helps you as a vSphere administrator leverage both technologies in the best way possible and in accord with best practices. Each feature is extremely easy to enable and configure in the benefits that both technologies bring to the table. By using few simple clicks in the properties of your vSphere Clusters, you can quickly start benefiting from these available cluster-level features.



